
郭倩倩, 王星惠, 张从巧
(安徽大学 经济学院, 合肥 230601)
大豆不仅是我国重要的粮食作物之一,也是我国进口量最大的农产品,因此大豆在国民经济中占有重要地位.自1993年我国建立大豆期货市场以来,交易量已从初始的860.69万手增加到72.69亿手(截至2021年底),为稳定我国大豆价格和粮食安全提供了重要保障.近年来,受国内外多种因素的影响,大豆期货价格处于总体上涨的波动趋势中,因此建立有效的大豆期货价格预测模型对规避大豆价格波动风险和保证我国粮食安全具有重要意义.目前,大豆价格预测方法主要分为两类:一种是利用时间序列模型的线性预测方法(ARIMA[1]、VAR[2]、GARCH[3]等模型)进行预测.该类方法具有操作和计算简单的优点,但对数据的要求较高,而且对非线性时间序列预测的精度和稳定性较低.另一种是利用机器学习的方法(SVR[4]、ANN[5]、LSTM[6]等模型)进行预测.该类方法虽然操作相对复杂,但由于其具有强大的非线性趋势拟合能力(可以更好地捕获数据之间的潜在关联),因此可有效挖掘数据.
近年来,分解集成方法(如EMD、EEMD、CEEMDAN等)因能够更好地捕获到原始序列中不同粒度的特征信息而受到学者的广泛关注,并被应用于多种产品的价格预测中[7-14].2020年,贺毅岳等[15]针对股票市场指数提出了一种基于CEEMDAN -LSTM的预测模型.该模型首先将原始序列分解为若干特征明显的简单序列,然后再利用单一LSTM模型捕获序列在不同频率下的波动性特征.研究显示,该方法可大大改善构建模型的效率和预测精度.但由于不同频率序列在实际中常会表现出不同的趋势,因此单一模型往往难以同时捕获到序列中的其他线性或者非线性特征.为此,本文构建一种基于CEEMDAN的多频优化组合模型,即通过不同单一模型的特性以充分提取不同频率序列的波动特征,以此进一步提高模型的预测精度.
1.1 CEEMDAN分解方法
CEEMDAN是一种基于EEMD改进的分解方法,它可以有效解决EEMD分解中因添加白噪声序列而导致的计算复杂度增加的问题.
CEEMDAN分解方法的具体步骤为:
1)首先确定第i次添加的白噪声ωi(t)和幅值εk, 然后在原始序列中加入白噪声ωi(t)εk后对其进行EMD分解,并将分解得到的多个子序列IMF均值作为第1阶段的cIMF1(t),即:
2)计算第1阶段残差r1(t), 其计算公式为:
r1(t)=x(t)-cIMF1(t).
(2)
3)将经过EMD分解后的噪声和第1阶残差相加,得到一个新的序列.对该序列进行EMD分解并求集合平均值即可得第2阶段的cIMF2(t):
4)计算第k阶残差rk(t), 其计算公式为:
rk(t)=rk -1(t)-cIMFk(t).
(4)
5)重复第3步,由此可得到第k+1阶段的cIMFk +1(t), 即:
Ek(ωi(t))εk].
(5)
6)重复第4步,且当残差序列不可再分解时,将其记为最终的残差(r(t)), 即:
(6)
原始序列x(t)的最终分解结果可表示为:
(7)
1.2 预测方法
1.2.1ARIMA(p,d,q)模型
ARIMA(p,d,q)模型是将自回归模型(AR)、移动平均模型(MA)和差分法相融合而成的一种模型,其中p为自回归向,d是数据进行差分的阶数,q为移动平均项数.ARIMA(p,d,q)模型的表达式为:
yt=θ1yt -1+…+θpyt -p+εt-
θ1εt -1-…-θpεt -p.
(8)
1.2.2SVR模型
SVR模型是一种假设能容忍预测值和标签值之间偏差最多为ε的回归模型.如图1所示,该模型通过在线性函数f(x)两侧构建一个偏差为ε的隔离带,以最小化偏差ε与总损失来最优化模型.该模型可表示为:
(9)
其中:C为正则化常数;
lε是ε-不敏感损失函数,即损失函数的计算仅针对隔离带外的样本.

图1 SVR的原理示意图
`1.2.3BPNN模型
BPNN是一种通过误差反向传播算法训练的多层前馈神经网络模型,其网络结构由输入层、隐藏层、输出层组成,如图2所示.

图2 BPNN的结构示意图
BPNN的训练过程如图3所示.训练时:首先根据定义好的损失函数计算预测值和真实值之间的误差,并对其进行求导;
然后沿着梯度最小的方向反向传播误差,以此更新网络中每一层的权重参数;
最后再进行正向计算.循环反复此过程,直到损失函数值趋于稳定.

图3 BPNN的训练过程
1.2.4LSTM模型
LSTM是一种特殊循环神经网络模型,它可有效解决简单循环神经网络中存在的梯度爆炸或消失的问题.LSTM网络结构由单元状态、遗忘门、记忆门和输出门组成,如图4所示.

图4 LSTM网络结构图
LSTM 的前向计算过程如下:
1)将当前的输入xt和上一个状态传递下来的ht -1进行拼接,并以此作为输入.
2)对长期状态进行控制,主要分为3个阶段:
第1阶段为忘记阶段.该阶段主要对上一个节点传来的输入进行选择性忘记,并将输出信号ft作为忘记门控.ft的计算公式为:
ft=σ(Wf·(ht -1,xt)+bf),
(10)
其中σ为sigmod神经网络层,ft为0到1之间的数(1代表信息完全保留, 0代表信息完全遗忘).

it=σ(Wi·(ht -1,xi)+bi).
(11)
(12)
第3阶段为更新阶段.模型得到遗忘门和记忆门后更新单元状态(根据公式(13)),t时刻的单元状态Ct可表示为:
(13)
式中⊙表示哈达玛积.
3)根据公式(14)计算Ot, 并将得到的Ot作为输出门控.根据公式(15)计算ht,并将得到的ht作为下一时刻的输入信号并传递到下一时刻.
Ot=σ(Wo(ht -1,xt)+bo),
(14)
ht=Ot⊙tanh(Ct).
(15)
1.3 预测流程
构建对大豆期货收盘价进行预测的多频优化组合模型的方法为:首先,对大豆收盘价进行CEEMDAN分解,由此得到6个不同频率的IMF分量和1个残差趋势项;
其次,求出各个IMF分量之间的皮尔逊相关系数,并基于皮尔逊相关系数对各个IMF分量进行聚类;
再次,对聚类得到的高-中-低频分项和趋势项进行经济意义的解释,并运用SVR、ARIMA、LSTM、BPNN模型对各个分项进行预测,以此选择出各个分项中预测效果最好的模型;
最后,组合各个分项的结果,由此得到最终的预测结果.组合模型的预测流程如图5所示.
1.4 模型的评价指标
评价指标采用均方根误差(RMSE)、平均绝对误差(MAE)和对称平均绝对百分比误差(SMAPE),各评价指标的值越小,表明模型的精度越高.各评价指标的计算公式为:
(16)
(17)
(18)
其中:Yi表示实际值,Y′i表示预测值,n表示预测期数.
2.1 数据来源与选取
本文数据来源于新浪财经网(https://finance.sina.com.cn/),样本区间为2009年8月27日至2021年7月6日的所有交易数据.在数据中剔除日成交量为0的所有收盘价格之后,最后收集到的数据为2 880条.为了减少因数据量较大而产生噪音,本文采用重采样技术(降采样)对数据进行预处理.经预处理后共得到614条数据.图6为数据处理后的大豆期货价格的序列走势图.实验时,本文选取数据集的前80%数据作为训练集,后20%数据作为测试集.

图6 大豆期货价格的序列走势
2.2 大豆期货收盘价的分解和重构
本文运用Python 3.7软件对大豆期货日价格进行了CEEMDAN分解,由此共分解得到了6个不同频率的本征模函数(IMF1 -IMF6)和1个残差趋势项,如图7所示.
利用Numpy库中的corrcoef函数计算出的IMF1至IMF6之间的皮尔逊相关系数见表1.基于皮尔逊相关系数对各个IMF分量进行聚类的结果见图8.
由表1可以看出,IMF1和IMF3、IMF2和IMF5、IMF2和IMF6、IMF4和IMF6之间的相关系数在1%水平下显著.由图8可以看出:IMF1、IMF2、IMF3和IMF4为高频项, IMF5为中频项,IMF6为低频项.

图7 大豆价格的CEEMDAN分解结果

表1 皮尔逊相关系数值

图8 基于皮尔逊相关系数的聚类图
为分析各分项的特征,利用Python科学计算包计算了各个分项的p值、周期、方差贡献率以及各分项与原序列的相关系数,结果见表2.由表2可知:
1)高频项(IMF1-IMF4)的平均周期为4.451,其与原序列的相关系数为0.284,p值为0.000(远低于0.05的水平,即通过显著性检验),表明原序列和高频项之间存在相关性,但相关程度较弱;
高频项的方差贡献率为9.307%,表明高频项对大豆期货收盘价的解释力较小.图9为大豆期货收盘价和各分项重构后的走势.由图9可以看出,高频项的均值始终在0附近上下波动,这是由市场短期不规则事件引发的价格变化导致的.
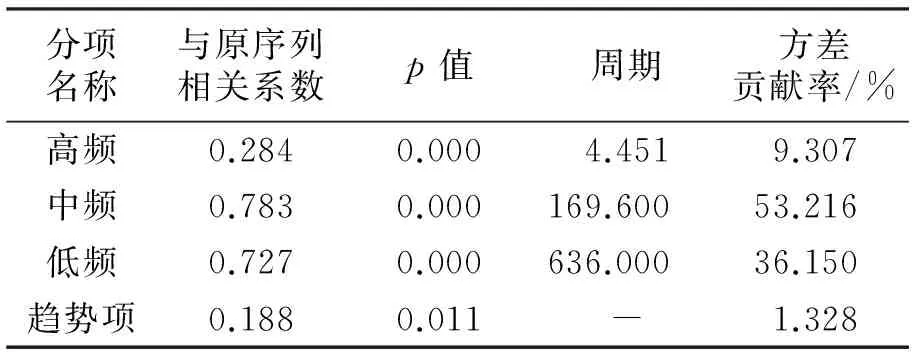
表2 各分项的周期和方差贡献率

图9 大豆期货收盘价和各分项重构后的走势
2)中频项(IMF5)的平均周期为169.600,其与原序列的相关系数为0.783,p值为0.000(通过显著性检验),表明原序列和中频项之间存在相关性,且相关程度较强;
中频项的方差贡献率为53.216%,表明中频项对大豆期货收盘价的解释力较强.从图9可以看出,中频项与原序列的波动基本保持一致,该结果同时也验证了上述分析结论.此外,从图中还可以看出中频项能够反映出因重大事件导致的大豆价格变化,如2016年12月国务院推出农业补贴政策转型后,大豆期货价格总体呈现下降趋势(2017年1月10日至2019年12月3日).
3)低频项(IMF6)的平均周期为636.000,其与原序列的相关系数为0.727,p值为0.000(通过显著性检验),表明原序列和低频项之间存在相关性,且相关程度较强;
低频项的方差贡献率为36.150%,表明低频项对大豆期货价格也具有一定的解释力.
4)残差趋势项不存在周期性,其与原序列的相关系数为0.188,p值为0.011(通过显著性检验),表明原序列和趋势项之间存在相关性,但相关程度弱.残差趋势项的方差贡献率为1.328%,表明趋势项对大豆收盘价的解释力较小.由图9可知,大豆期货价格虽然存在较大波动,但会逐渐回到趋势价格附近.这表明,趋势项可以反映大豆期货价格的长期趋势.
2.3 大豆期货收盘价的预测和对比
用SVR、BPNN、ARIMA、LSTM 4个模型对分解重构后的各个分项进行预测,结果见表3.从表3可以看出,在高频项中评价LSTM模型的3个指标几乎都取得了最优的结果.其原因是LSTM模型在面对波动性较强的高频序列时可以考虑到之前序列的特征信息,进而使得模型可以有效捕获到序列中的非线性特征.因此,本文选择LSTM模型作为高频项的预测模型.

表3 4种模型对各分项的预测结果
在中频项的预测结果中,ARIMA模型虽然在SMAPE评价指标上低于其他3个模型,但在RMSE和MAE评价指标上显著优于其他3个模型;
因此,经综合考虑后,本文选择ARIMA模型作为中频项的预测模型.
在低频项的预测结果中,BPNN模型的各项评价指标均优于其他模型,因此本文选择BPNN模型作为低频项的预测模型.
对比表3中各单一模型在趋势项上的各评价指标结果可知,除了SVR模型外其他模型均取得较好的预测效果.由于ARIMA模型在捕获趋势项的线性变化上具有更明显的优势,因此本文选择ARIMA模型作为趋势项的预测模型.
基于上述分析,本文集成LSTM、ARIMA(2,2,1),BPNN、ARIMA(3,2,2)模型构建了多频优化模型.图10为模型在测试集上的预测效果图.由图10可看出,多频优化组合模型能够很好地捕获到大豆期货收盘价的波动规律,即模型的拟合能力较强,由此表明模型具有良好的预测效果.
为验证本文构建的多频优化组合模型的优越性,设计了多组对比实验.实验结果如表4所示.由表4可知,除EMD -LSTM组合模型外,其他基于CEEMDAN分解的组合模型的预测效果均显著优于各单一模型.其原因是CEEMDAN能够克服EMD在分解过程中出现的自适应性差及模态混叠的问题.此外,在基于CEEMDAN分解的组合模型中,多频优化组合模型(重构)的预测效果显著优于CEEMDAN -BPNN和CEEMDAN -LSTM未重构组合模型,这表明经分解重构后的模型在预测精度上更具有优势:因此,本文提出的多频优化组合模型更适用于大豆期货价格的预测.

图10 多频优化组合模型的预测效果图

表4 不同模型对大豆期货收盘价的预测结果
利用本文构建的多频优化组合模型对我国大豆期货价格进行预测表明,该模型可以综合考虑影响大豆价格的多种因素,并依据不同单一模型的特性可充分提取重构后不同频率序列的波动特征,使得模型的预测精度显著优于其他单一模型以及EMD -LSTM、CEEMDAN -BPNN(未重构)、CEEMDAN -LSTM(未重构)等组合模型,因此该模型可为大豆期货价格的预测提供良好参考.在今后的研究中,我们将探讨其他单一模型在组合模型预测中的应用,以进一步提升模型的预测精度.
猜你喜欢 优化组合期货价格收盘价 新冠疫情对黄金期货价格的干预影响研究中国市场(2021年34期)2021-08-29“三螺旋”优化组合实践教学模式在高职课程教学中的应用计算机教育(2020年5期)2020-07-24红枣期货价格大涨之后怎么走今日农业(2019年10期)2019-06-26股神榜股市动态分析(2018年21期)2018-06-07股神榜股市动态分析(2017年40期)2017-11-01股神榜股市动态分析(2017年22期)2017-06-19浅析国际原油价格的波动原因现代营销·学苑版(2016年11期)2017-01-19股神榜股市动态分析(2016年32期)2016-10-25基于ARIMA模型的沪铜期货价格预测研究商(2016年27期)2016-10-17赛前训练中运动员竞技能力的优化组合中国体育教练员(2015年2期)2015-04-16