
岳溪朝冯燕刘健于烨泳席慷杰钱权
(1.上海大学计算机工程与科学学院,上海200444;2.国家超级计算无锡中心,江苏无锡214072;3.上海大学材料基因组工程研究院材料信息与数据科学中心,上海200444;4.之江实验室,浙江杭州311100)
材料基因组工程融合了高通量计算、高通量实验和材料数据库,旨在实现材料研发的“时间减半和成本减半”,而基于材料数据库的数据驱动新材料研发被认为是材料研发的第四范式[1].然而,材料数据种类多(实验、计算、生产、文献数据等)、表现形式多样(文本格式、图像格式、视频格式等),因此如何规范化存储材料数据是相关研究的首要问题.在材料数据标准化方面,国际化标准组织最早曾发布了产品模型数据交互规范(standard for the exchange of product model data,STEP)[2],通过编写材料数据手册的方式实现存储、查询数据.在关系数据库出现后,材料科学研究人员更倾向于将材料数据存储在关系数据库中.随着数据库技术的发展,材料领域出现了一大批材料数据库[3],一些较为知名的材料数据库如表1所示.此外,研究人员使用本体、知识图谱等技术来增强材料数据语义性,进一步扩展了材料数据库的使用范围,其中MatOWL[4]较为著名.
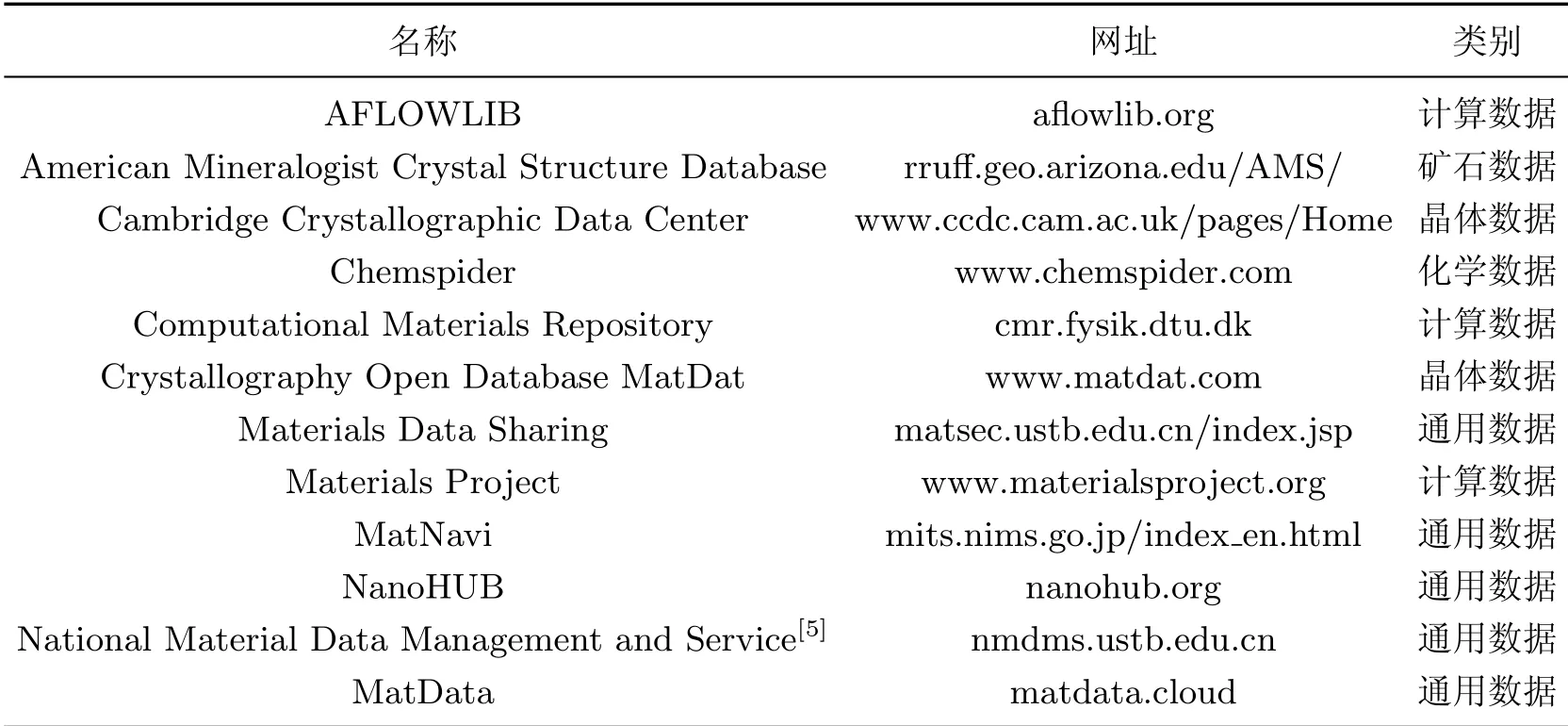
表1 一些知名材料数据库Table 1 Some well-known materials databases
计算材料学从微观、介观到宏观等不同尺度进行材料微结构模拟及性能计算,但通常计算量大、应用范围受限.近年来,随着机器学习和人工智能的迅速发展,越来越多的传统学科开始使用机器学习方法进行研究.在材料学领域,使用机器学习方法,从数据出发,运用数据内部蕴含的统计规律建立模型,可以为材料学研究提供有价值的指导.然而,材料数据非常宝贵,尤其是敏感的工艺参数,因此需要研究如何在保护数据隐私的情况下进行机器学习.
此外,由于材料领域知识贯穿于数据驱动的新材料研发的各个环节,采用知识图谱的知识库进行异构材料数据的集成与导航,以实现数据与知识双驱动的材料研究,将进一步提高新材料的研发效率.因此,材料基因工程专用数据库平台将有助于提高材料数据质量,简化机器学习模型的部署和使用,并通过机器学习方法及材料知识图谱,使机器学习在材料科学研究领域得到更好的应用.
材料基因专用数据库体系结构如图1所示,包括数据层、融合层、管理层、学习层和知识层这5个层次,反映了材料基因工程从材料数据→材料信息→材料知识这一基本认识规律.图1中,LIMS(laboratory information management system)代表实验室信息管理系统,ETL(extract transform load)代表数据抽取、转换和加载,XML(extensible markup language,XML)代表可扩展标记语言,XSD(XML schema definition)代表XML模式定义,SPARK是一款分布式计算框架,REST(representational state transfer)代表表述性状态转移.
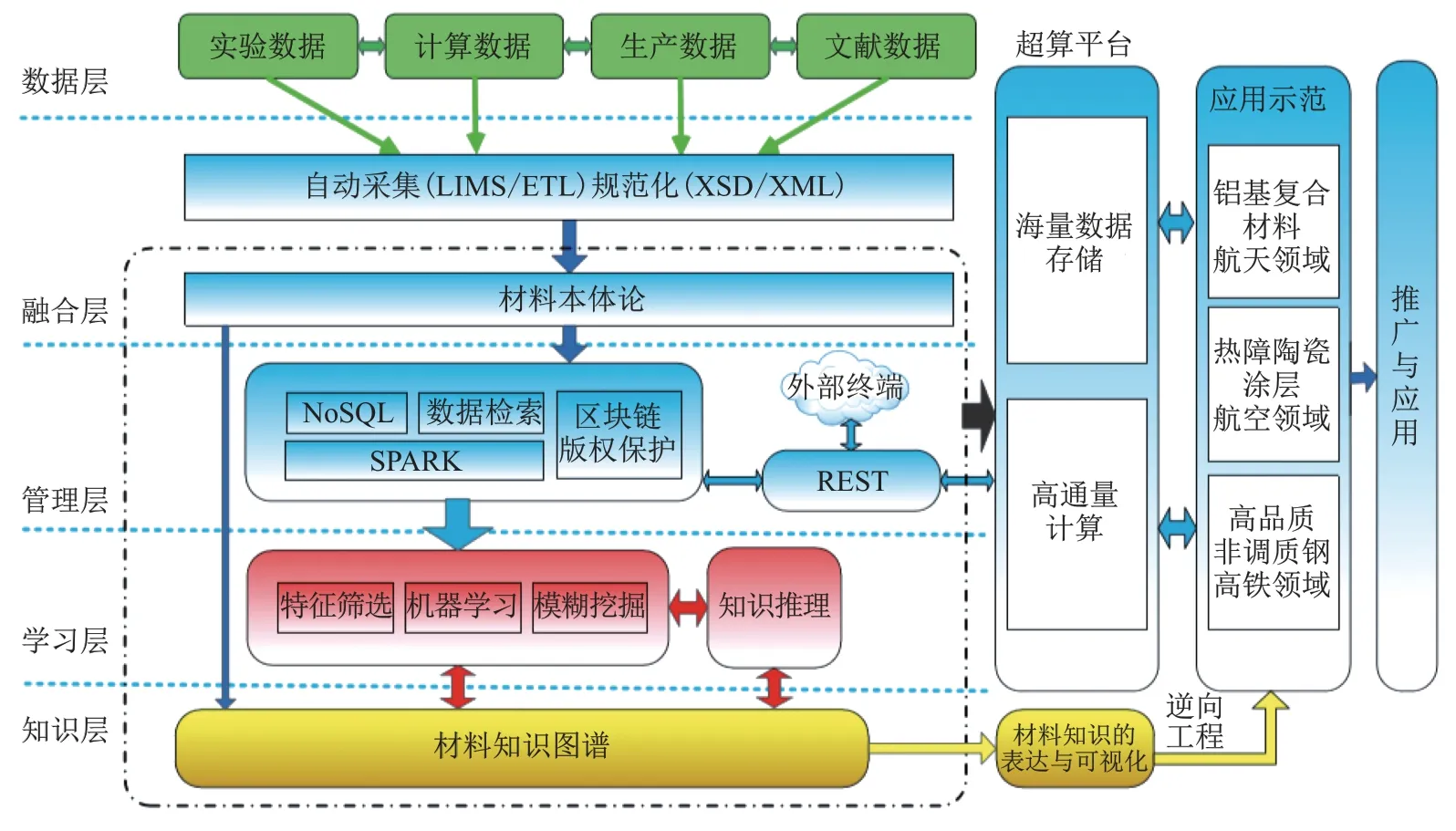
图1 材料基因组工程专用数据库层级架构Fig.1 Hierarchical architecture of database for material genome engineering
数据层:对于材料实验、计算、生产和海量文献等多源数据,在标准统一的协议下进行数据的采集、规范化与网络传输.
融合层:在数据采集的基础上,结合材料数据语义进行多源、异构材料数据的集成与融合.
管理层:采用关系型和无模式NoSQL混合存储、分布式内存计算等大数据处理技术,实现专用数据库的数据存储与开放共享,并在超算平台上实现系统部署和运行.
学习层:采用特征筛选、机器学习等方法实现数据驱动,以及基于知识图谱采用知识推理技术,发现知识驱动的材料“组分-工艺-结构-性能”间的内禀关系,优化材料设计、加工工艺与提升材料性能.
知识层:通过数据与知识之间的传递与反馈,实现对机器学习结果的语义表达与知识管理,并通过构建知识图谱实现数据与知识的可视化展示.
最后,结合高性能铝基复合材料、热障陶瓷涂层、非调质特殊钢3类材料进行示范应用和推广.
接下来,将就专用数据库平台中几个关键部分,如材料数据的规范化、面向材料数据的机器学习以及模型跨域部署、保护材料数据隐私下的机器学习等方面进行重点介绍.
1.1 材料数据规范化表示
材料数据具有来源众多、类型繁杂、列多变、高维稀疏、关系复杂等特点,材料数据若要满足可发现(findability)、可访问(accessibility)、可互操作(interoperability)、可重用(reusability)原则[6],规范化处理是前提和基础.本工作提出的材料数据规范设计方案以层次化设计思想为基础,将复杂数据规范分成多个不同层级,从最简单的结构开始,首先为每一层级制定子规范,然后逐步组合子规范,最后得到完整数据规范.
就具体实现技术而言,将材料数据以XML[7]格式进行存储.针对复杂的材料实验或者计算数据,首先使用巴科斯范式(Backus-Naur form,BNF)这一上下文无关文法的形式化标记方法,来设计层次化的数据规范方案.在此基础上,使用XSD[8]实现巴科斯范式,具体过程如图2所示.包含XSD格式的数据规范可保证数据结构的完整性及数据类型的准确性.此外,借助可扩展样式语言(extensible stylesheet language,XSL)[9]实现数据的定制化展示和定制化下载,便于数据的页面展示和导出,实现与机器学习模块的无缝衔接.基于XSD/XSL的材料数据规范化具有规范性、语义性,便于数据扩展和数据共享,可为简单数据、表格型数据和非结构化数据等多种多源异构数据提供规范化表示.
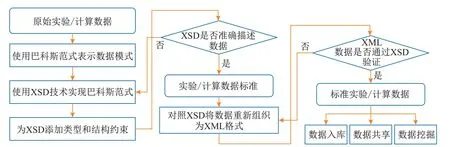
图2 材料数据规范化处理流程Fig.2 Processing flowchart of materials data standardization
1.2 面向材料数据的机器学习及模型跨域部署
材料数据由于其本身的特异性,使得机器学习的挑战主要体现在以下方面:小样本(样品少或样品的实验结果分散性大,遵循某种分布的样本少)、数据的维度高(相比于样本量,样本的维度高,数据呈现高稀疏性)、数据含噪声(制备或者表征中引入的误差)、多模态融合(如材料微结构的图像表示,以及工艺数据的自然语言刻画)等.目前围绕材料数据已经开展了很多相关的机器学习研究[10].
更为重要的是,利用宝贵的材料数据建立的机器学习模型如何在不同组织间跨域部署以及快速应用是一个难点.不同组织内由于面对的材料体系不同,因此需要对快速部署的机器学习模型进行迁移,为新的目标领域提供模型支撑.机器学习模型的跨域部署过程如图3所示,首先通过导出工具将训练好的机器学习模型导出为统一的中间表示,然后部署到可以解析并执行该中间表示的运行环境,即可完成模型迁移和部署.图3中,PMML(predictive model markup language)代表预言模型标记语言,ONNX(open neural network exchange)代表开放神经网络交换,BIN(binary)代表二进制文件.
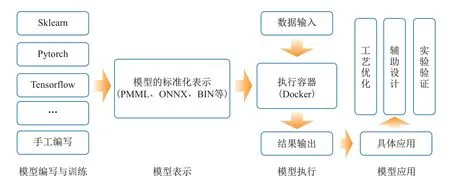
图3 机器学习模型跨域部署流程Fig.3 Flowchart of cross-domain deployment of machine learning model
1.2.1 机器学习模型调度与运行
为了兼容ONNX[11]、PMML[12]等多种机器学习模型导出格式,数据库平台根据所上传模型的格式创建不同的机器学习模型运行环境,并将输入数据转换为运行环境所需格式,最终将不同环境得到的计算结果进行输出.如图4所示,为避免过多的机器学习任务并发执行而产生线程的频繁创建、销毁及切换,防止内存不足导致运行错误,数据库平台采用任务队列及线程池技术,确保正在执行的机器学习任务数与当前硬件环境相匹配.机器学习模型仅在使用时被加载进内存,执行结束后,自动地对模型进行垃圾回收,直到下次使用时才会重新加载.
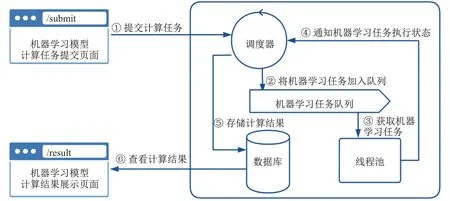
图4 机器学习任务在数据库平台上的调度流程Fig.4 Scheduling process of machine learning tasks on the database platform
1.2.2 机器学习模型版权保护
经数据训练后的机器学习模型是宝贵的资产,数据库平台采用区块链技术对机器学习模型版权进行保护[13].区块链通过分布式记录来确保版权的所有人信息不会被轻易篡改,从而达到版权保护的目的.考虑到版权保护主要涉及版权所有人以及版权交易信息,因此区块链中会以版权所有人的变更信息来记录交易情况,用户可以追溯任何一条版权交易的记录,用来维护自身权益.同时,数据库平台设计了一种组合竞拍算法,提供适合多个版权的组合拍卖服务.该算法可以通过不同用户的出价,自动计算出最优于卖家的出价组合进行拍卖.
机器学习模型跨域部署模块的主要运行界面如图5所示,图中SVR(support vector regression)代表支持向量回归.用户可上传、搜索、使用、评估机器学习模型,模型拥有者可以自行选择是否通过区块链对已上传的模型进行版权保护.对于已上传区块链的模型,系统会为其生成一个ID,用于交易、拍卖或者验证版权所有人信息等.
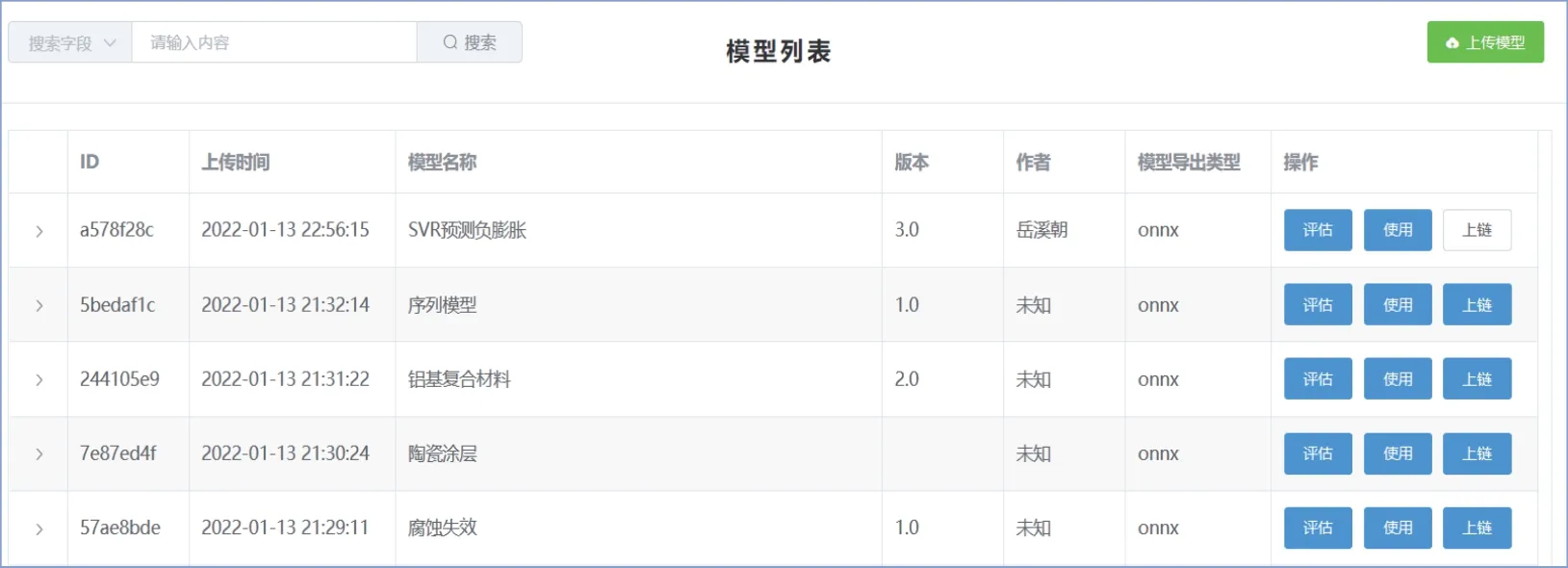
图5 机器学习模型跨域部署运行界面Fig.5 Running interface of machine learning model cross-domain deployment
1.3 材料数据隐私保护下的机器学习
材料数据在很多情况下是“小数据”,很难训练出泛化能力出众的模型.解决小样本问题可以通过数据增强来扩充数据集,但是增强的数据会与实际数据存在差异.除此之外,由于材料数据需要花费大量的人力和物力,使得很多研究机构不愿共享数据.而联邦学习[14]可以解决该问题,即在不泄露参与方数据的情况下,又能让多个参与方一起协同训练出一个共享模型.
根据数据的分布特征不同,联邦学习分为横向联邦学习、纵向联邦学习和联邦迁移学习(见图6).以用户2为例,横向联邦学习适用于数据集中共享相同的特征空间,但样本不同的场景;纵向联邦学习适用于数据集共享相同的样本ID空间,但特征空间不同的场景;联邦迁移学习适用于数据集不仅样本不同,而且特征空间也不同的场景.
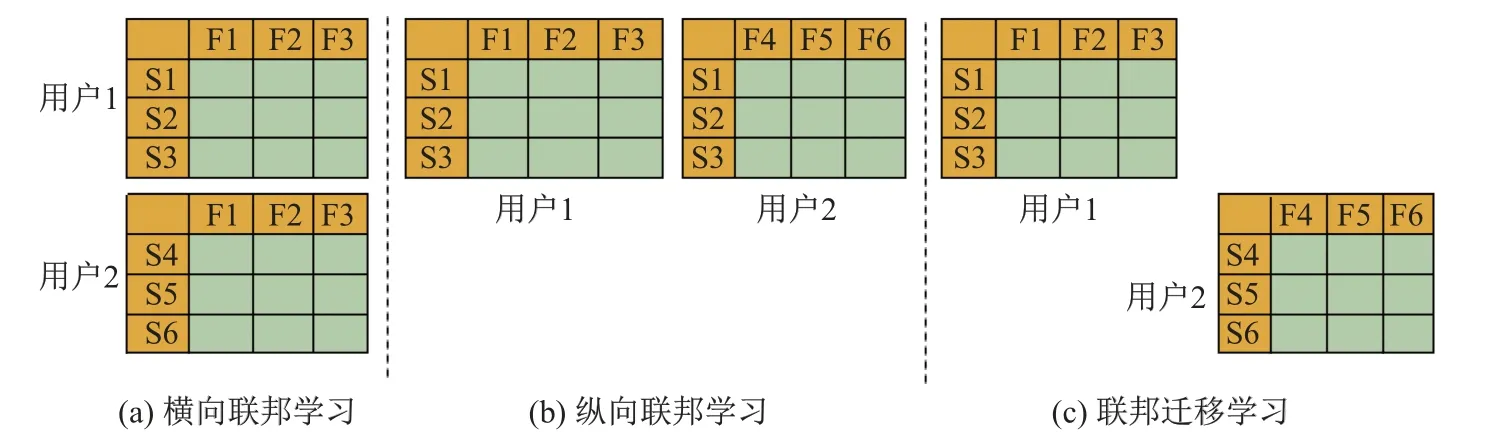
图6 不同联邦学习下的数据分布Fig.6 Data distribution under different federated learning
在联邦学习中,主要包括3种隐私保护策略:差分隐私、同态加密和安全多方计算.差分隐私可对联邦学习训练过程中的数据进行扰动;同态加密可对联邦学习训练过程中的数据进行加密,使学习过程基于密文进行;安全多方计算可对联邦学习的整个训练过程进行保护.
(1)差分隐私是Dwork等[15]在2006年首次提出的一种隐私定义.差分隐私可以使函数的输出结果对数据集中的任何特定记录都不敏感,因此能被用于抵抗成员推理攻击.(ε,δ)-差分隐私的定义如下.
定义1对于只有一个记录不同的两个数据集D和D′,随机化机制M可保护(ε,δ)-差分隐私,并且对于所有的S⊂Range(M),有
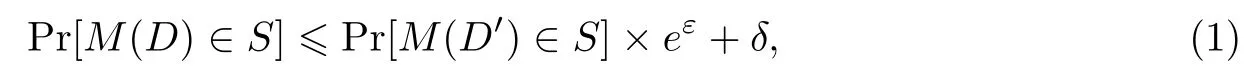
式中:ε表示隐私预算;δ表示失败概率.
在机器学习中,差分隐私添加噪声的机制主要包括拉普拉斯机制、指数机制和高斯机制.差分隐私根据噪声扰动的使用方式和位置,可以对输入、目标函数、算法以及输出添加扰动.
(2)同态加密由Rivest等[16]在1978年提出,是一种不需要对密文进行解密的密文计算方式.目前的同态加密方法主要分为3类:部分同态加密、些许同态加密和全同态加密.同态加密方法由一个四元组组成,

式中:KeyGen表示密钥生成函数,可以根据密钥生成元g生成密钥对{pk,sk}=KeyGen(g);Enc表示加密函数;Dec表示解密函数.
在机器学习中,同态加密通常用于避免梯度下降过程中的数据泄露,对梯度或权重进行加密,然后将加密后的梯度或权重发送给各参与方进行解密和模型更新.
(3)安全多方计算[17]要求每个参与方{P1,P2,···,PN}在保护个人隐私的前提下共同计算一个函数f,这一过程中既要保证输出结果的正确性,也要保证输入、输出信息的隐私性.具体定义为
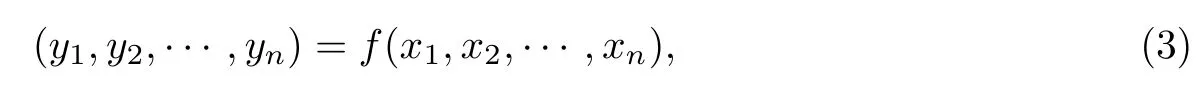
每个参与者Pi在保护自身xi隐私的同时得到正确的Yi.
安全多方计算通常使用3种不同框架来实现,包括不经意传输、秘密共享和阈值同态加密,其中秘密共享是安全多方计算的核心.在机器学习中,安全多方计算的关键点是在没有可信第三方的条件下,参与训练各方安全地计算一个共同的约束函数.以秘密分享技术以及多层感知机对日本国立材料科学研究所(National Institute for Materials Science,NIMS)钢数据集[18]中材料硬度的预测为例,在数据集上模拟的秘密共享客户端断线的情况下,材料硬度的预测值和测量值的对比如图7所示.从实验结果可以看出,基于安全多方计算的隐私保护策略可以在保护数据隐私的情况下,使模型预测精度维持在较高的水平.
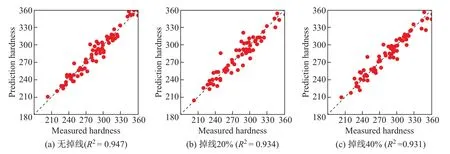
图7 NIMS钢数据集不同比例客户端掉线情况下预测准确率对比Fig.7 Comparisons of prediction accuracy on NIMS steel dataset with different proportions of client dropout
1.4 从材料数据库到知识库
材料领域知识贯穿于数据驱动新材料研发的各个环节,传统的知识表示有基于规则、基于框架等方法[19-20],目前较常用的是基于知识图谱的方法.基于知识图谱的知识库一方面可以实现异构材料数据的集成与导航,另一方面可以基于知识图谱中的领域知识丰富机器学习模型,实现数据与知识双驱动的材料领域研究[21].
针对多源异构的材料数据,可以利用网络本体语言(web ontology language,OWL)[22]进行集成.本体包含了对某一领域中概念和性质的描述,通过概念之间的关系来实现对数据实体的限定和规范,进而将对数据的操作转换成对概念的操作,从而扩大了对多源异构数据的兼容性.因此,通过构建OWL可以将概念与概念、概念与数据以及数据与数据之间连接起来,并通过图数据库(如Neo4j)进行存储,从而有效解决多源异构数据的集成问题.
OWL主要由个体(individuals)、属性(properties)和类(classes)组成,其中individuals表示每条具体数据,properties表示数据之间的关系,而classes表示数据所属的概念层.知识图谱的构建流程(以Neo4j图数据库作为存储媒介)如图8所示,图中CSV(comma-separated values)代表字符分割值,API(application programming interface)代表应用程序编程接口.首先,对来源于数据库平台的不同数据模型进行解析,提取其中的概念和数据,并根据OWL规则将概念层和数据层分别转换成individuals、properties和classes,完成OWL文件;然后,利用OWL API对得到的OWL文件进行解析和本体创建.
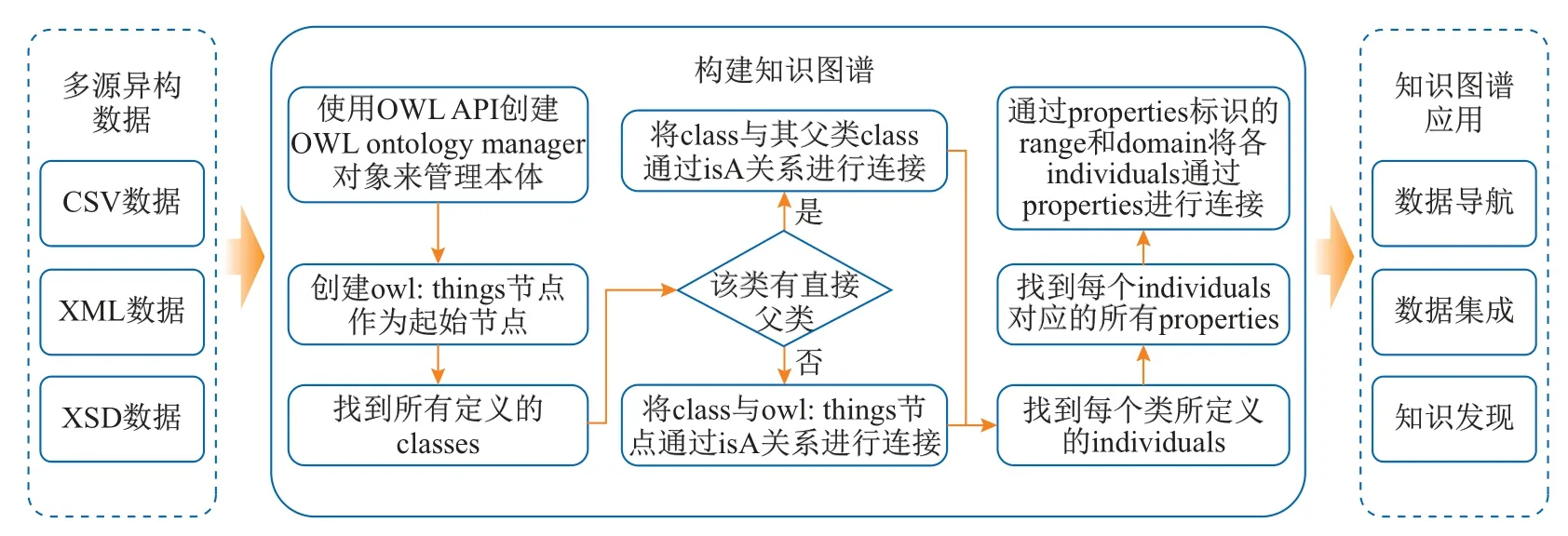
图8 OWL构建流程图Fig.8 Flowchart of OWL construction
在Neo4j中,一个本体为一张图,本体的起始节点是owl:things,所有的classes节点都由此进行扩展.以锡焊料性能数据中的基本信息表为例(见图9),概念层仅包含从异构数据模型中抽取的表名及字段名构成的classes概念类节点,类与类之间主要通过父子关系进行连接.而数据层由概念层不同类组成的实体数据及实体数据之间的关系组成,因此通过对异构数据模型进行本体构建,从概念层上为数据提供了一个统一的操作接口,从而实现跨域数据的集成、查询、导航等功能.对于已通过模板校验并上传至数据库中的数据,知识图谱模块使用从数据归档模块导出的数据,利用OWL进行集成,最终形成知识图谱.

图9 锡焊料知识图谱构建示例Fig.9 An example of Tin solder knowledge graph construction
除此之外,知识图谱的不断发展为数据与知识的双驱动材料研究模型提供了技术支持.知识图谱不仅能对机器学习中的挖掘结果进行知识表达,还能结合材料领域的知识模型和机器学习中的数据模型进行混合推理,从而提高模型的准确性、可靠性和可解释性[23-24].
2.1 数据库平台体系结构
整个数据库平台从功能角度可分为4大部分(见图10),分别是数据存储模块、数据归档模块、机器学习模型跨域部署模块、知识图谱模块.各模块之间通过RestAPI进行通讯,不同模块可分别部署在不同的物理机上.
图10 材料基因工程数据库平台系统结构Fig.10 System architecture of materials genome engineering database platform
(1)数据混合存储系统.材料数据存在多源异构等特性,本数据库平台采用关系型和非关系型相结合的混合存储模式,通过数据库适配器将不同类型的数据存入对应的数据库中.具体而言,使用PostgreSQL数据库存储用户、权限管理、元数据等关系型数据;使用MongoDB数据库存储图片、视频等非结构化数据;使用Redis数据库存储会话及用户状态等数据;使用Neo4j存储由知识图谱模块处理得到的图结构数据.所有数据库中的数据经数据聚合器处理后存入ElasticSearch,以提供高效的全文检索.
(2)数据归档模块.材料数据来源于多种录入方式,数据归档模块中的数据导入器可支持手工导入、批量上传、自动采集等多种录入方式.为避免录入方式多样带来的数据格式不规范问题,所有录入的数据需经过模板进行校验,校验通过则存入数据库中,否则返回报错信息.模板通过XSD文件进行定义,但手工编辑XSD文件具有较高门槛且容易出错.为方便用户创建模板,数据管理模块提供了模板设计器,以可视化的方式创建模板.数据导出器可根据用户自定义的XSL文件将已存入数据库的XML文件转换为HTML进行展示,或转换为CSV文件用于机器学习和知识图谱的构建.
(3)机器学习跨域部署模块提供机器学习模型的上传、评估、使用等功能.模型运行环境负责优化并运行已上传至数据库平台的模型;模型管理器负责模型格式正确性校验以及对模型运行环境的控制.用户上传模型至数据库平台后,无需配置相关运行环境即可使用该模型,且用户可直接使用从数据归档模块中导出的数据来评估该模型在特定数据集上的性能,或对特定数据集进行建模和预测以辅助材料领域研究.
(4)知识图谱模块通过数据归档模块获取数据,并转换为OWL后存储至数据混合存储系统中,提供实体关系查询以及知识图谱可视化展示功能.
2.2 数据库平台在超算上的部署
材料基因专用数据库已在无锡超算中心集群中部署,由9台服务器经虚拟化后组成云服务器构成硬件环境,其中5台服务器拥有4核心8 GB内存,3台服务器拥有16核心32 GB内存,1台服务器拥有48核心128 GB内存.所有虚拟机装有CentOS7操作系统,并位于同一网段中.外网访问集群需要通过虚拟专用网(virtual private network,VPN).连接VPN后,客户机可通过加密信道与服务器进行通讯.另外,数据库平台部署过程中,1台4核心8 GB内存的虚拟机用于部署Nginx作为负载均衡器及静态文件服务器,另外4台4核心8 GB内存虚拟机用于部署PostgreSQL、MongoDB、Redis、Neo4j,其余4台大内存虚拟机用于部署ElasticSearch、数据管理模块、机器学习跨域部署模块、知识图谱模块.
2.3 应用示例
图11显示使用机器学习进行材料正向预测及逆向设计的全流程.首先,对多源、异构的材料数据进行规范化,并存入数据库中;然后,使用数据库查询并导出结构化数据;接着,进行数据预处理,实施特征工程并训练机器学习模型,完成正向材料性能预测;最后,若进行逆向设计,即给定性能要求时,逆向给出工艺及成分设计参数,则需对机器学习模型进行选择并评估后,使用单目标或多目标算法进行逆向求解.
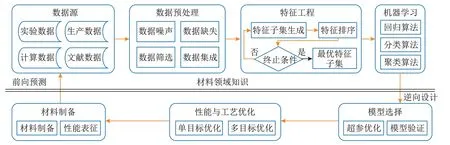
图11 材料正向预测与材料逆向设计流程Fig.11 Process of materials forward prediction and reverse design
下面以Mn-Zn-Sn体系反钙钛矿化合物负膨胀材料为例,说明材料基因数据库平台在材料逆向设计中的应用.该化合物的化学组成可表示为Mn3(MnxZnySnz)N,且要求x+y+z=1.逆向设计的目标是通过设计成分配比,使得发生负膨胀时的起始温度(T1)、结束温度(T2)以及负膨胀系数(α)符合应用需求.
(1)构建数据库.根据负膨胀材料数据的结构构建数据模板进行数据规范化描述.本数据库平台提供可视化的模板设计工具(见图12).模板设计器提供字符串、数字、带单位数值、日期、文件作为基本类型,以及列表、容器、选择、表格作为复合类型.同时,模板设计器还提供了历史模板复用功能.在负膨胀材料数据模板中,材料成分被设计为一个由元素名称及浮点数组成的表格,同时将起始温度、结束温度、负膨胀系数设计为浮点数.
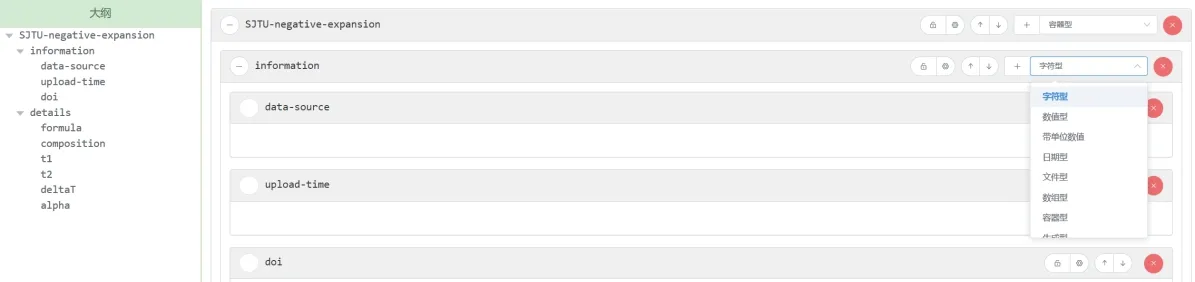
图12 可视化材料数据模板设计器Fig.12 Visual template designer for materials data
(2)数据的可视化展示.用模板设计器完成模板创建后,数据管理模块会生成数据录入表单,通过表单录入数据项后,模板校验其合法性,只有通过校验的数据才会以XML的形式存入数据库中,以确保入库数据的规范化.针对材料数据显示的多样性和个性化,专用数据库平台将数据存储和数据展示分离,通过设计不同的XSL样式文件,实现数据的个性化展示和下载.如图13所示,存入数据库中的XML数据可根据自定义的XSL样式文件通过数据导出器转换为HTML格式,在浏览器中进行显示;或通过XSL文件转换得到CSV结构化文件,用于机器学习或知识图谱构建.
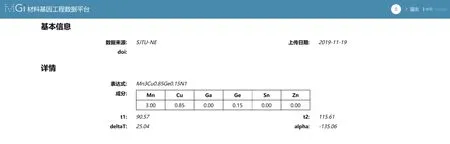
图13 负膨胀材料数据可定制化展示Fig.13 Customized data display of negative expansion materials
(3)机器学习模型构建和逆向设计.为了实现机器学习过程自动化与智能化,本数据库平台采用工作流的方式将机器学习建模、模型调参、模型选择和逆向设计集成起来,系统运行界面如图14所示.目前本数据库平台已集成数据预处理、建模、优化等8大类30余种算法.
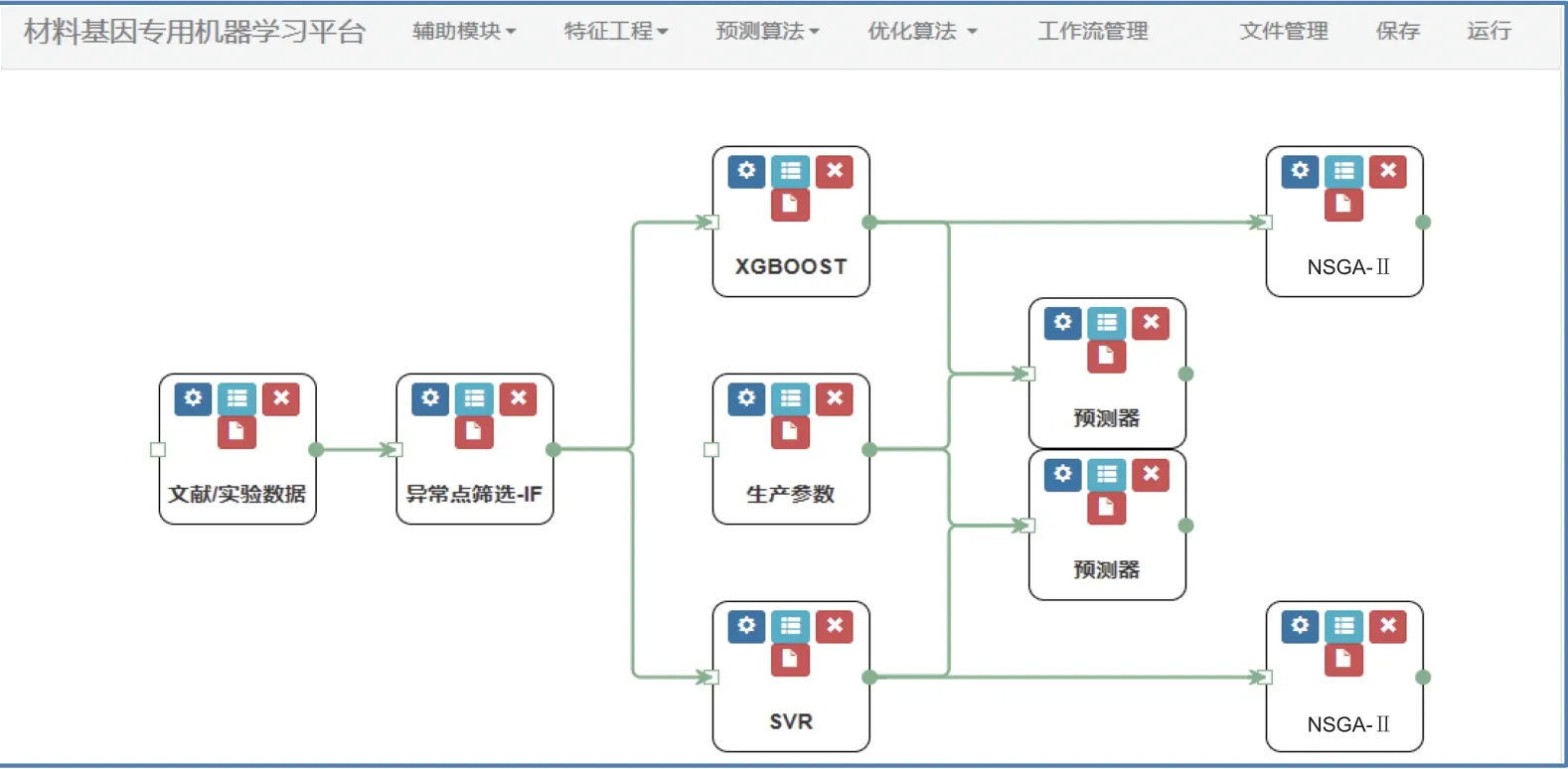
图14 负膨胀材料逆向设计工作流Fig.14 Reverse design workflow for negative expansion materials
(4)实验验证.从文献和实验中收集负膨胀数据131条,利用机器学习建模和多目标优化算法——非支配排序遗传算法-Ⅱ(non-dominated sorting genetic algorithms-Ⅱ,NSGA-Ⅱ)进行逆向设计,并结合实际应用需求筛选出2组可供实验的样本点.依照预测的材料组分,采用真空烧结与放电等离子烧结相结合的方法,制备出2种反钙钛矿锰氮化物,并测试负膨胀性能,测试结果如图15所示.模型预测结果与实验结果对比如表2所示,可以看出总体误差较小,平均预测精度88.25%,体现了数据驱动方法对于新材料研发的加速作用.

表2 负膨胀材料实验结果与模型预测结果对比Table 2 Comparison between experimental results and model prediction results of negative expansion materials
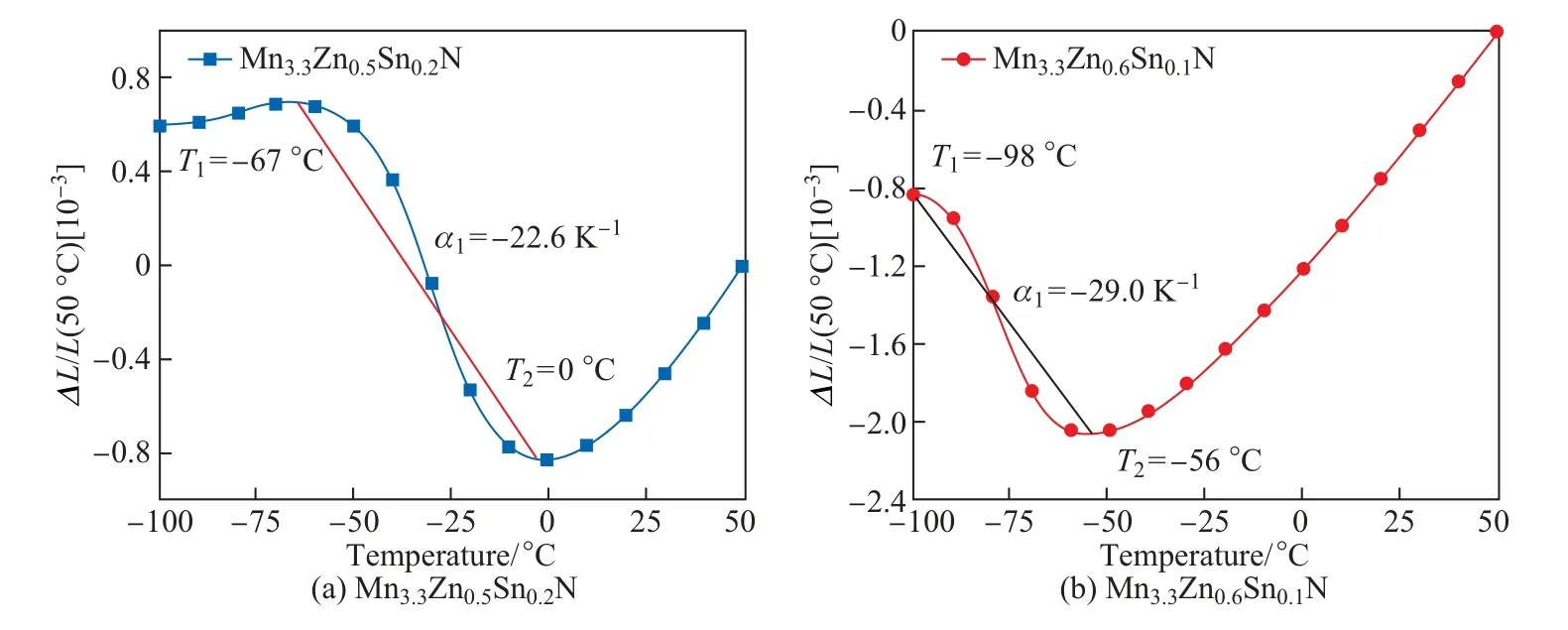
图15 Mn3.3Zn0.5Sn0.2N和Mn3.3Zn0.6Sn0.1N的负膨胀材料性能Fig.15 Negative expansion materials performance of Mn3.3Zn0.5Sn0.2N and Mn3.3Zn0.6Sn0.1N
材料基因专用数据库平台为材料数据的规范化存储、个性化展示和使用提供了一个集成框架,不但考虑了数据和模型的版权及隐私保护问题,还提供了机器学习模型跨域部署以及基于知识图谱的数据集成与导航功能.使用本系统对材料数据进行管理将大大提高数据的质量及可用性,在很大程度上解决了当下材料数据由于不规范而带来的数据预处理繁琐甚至数据不可用的问题.机器学习的跨域部署降低了运行机器学习任务的难度,允许在不泄露原始材料数据的同时共享机器学习模型.而知识图谱将为数据与知识的双驱动材料研究模型提供技术支持.
未来进一步的研究方向如下:①数据采集方面,如何更加便捷地转换不同来源的材料数据,尤其是文献数据,这对于丰富数据来源、扩大数据规模非常重要;②数据模板方面,如何平衡模板的灵活性与简洁性之间的矛盾,尤其是数据要方便导出进行机器学习十分关键;③机器学习模型方面,如何面向材料数据自身特性,研发适合材料数据的机器学习算法,尤其是研发隐私保护下的机器学习算法尤为迫切;④逆向设计方面,如何将材料学领域知识更好地与机器学习模型相结合,达到自动化与智能化的要求.
猜你喜欢 图谱模板机器 高层建筑中铝模板系统组成与应用建材发展导向(2022年20期)2022-11-03“植物界大熊猫”完整基因组图谱首次发布军事文摘(2022年16期)2022-08-24铝模板在高层建筑施工中的应用建材发展导向(2022年12期)2022-08-19基于伪谱法的水下航行体快速操舵变深图谱研究舰船科学技术(2022年11期)2022-07-15机器狗环球时报(2022-07-13)2022-07-13机器狗环球时报(2022-03-14)2022-03-14特高大模板支撑方案的优选研究建材发展导向(2021年20期)2021-11-20Inventors and Inventions考试与评价·高二版(2020年2期)2020-09-10未来机器城电影(2018年8期)2018-09-21图表新城乡(2018年6期)2018-07-09